One of my most frequently read articles is on how to use MBRAlign to align your virtual machine disks on Netapp storage. Well, after Netapp has released their new Virtual Storage Console (VSC4) the tedious task of using MBRAlign might be eased for some admins.
Optimization and Migration The new VSC4 console for vSphere has a new tab called Optimization and Migration. Here you are able to scan all or some of your datastores to check the alignment of your virtual machines. The scan manager can even be set on a schedule so that changes to the datastore will be recognized.
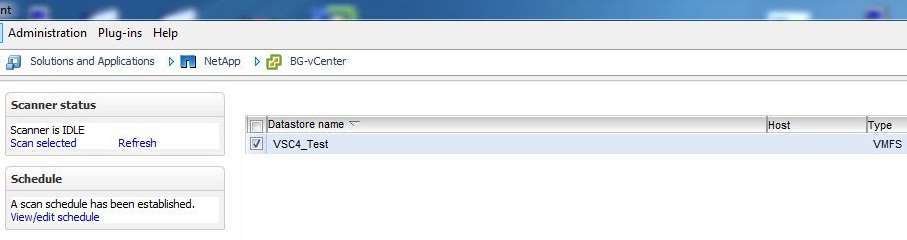 Once you have scanned your datastores you can go the the Virtual Machine Alignment section and see if your virtual machines are aligned.
Once you have scanned your datastores you can go the the Virtual Machine Alignment section and see if your virtual machines are aligned.
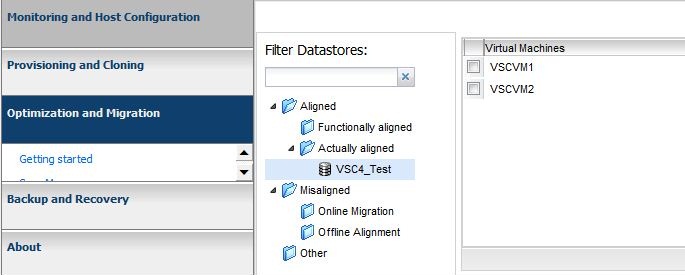
What if your virtual machines are not aligned already? Netapp has a new way to align your virtual machines without having to take them offline. Disclaimer: I’ve looked for documentation on exactly how this process works, but couldn’t find any. The information below is how I perceive it to work after testing in my lab. If there are any Netapp folks that have definitive answers on this process, or have documentation explaining this process, please post them in the comments and I will modify this post.
Instead of realigning the virtual machine, Netapp is creating a new datastore specifically built to align itself with the unaligned virtual machine. These new datastores are considered “Functionally aligned” because they make the vm appear to be aligned. If you were to put an “Actually Aligned” virtual machine in a functionally aligned datastore that vm would appear to be misaligned. It seems that Netapp is creating a new volume and has the starting offset match the virtual machine that is unaligned.
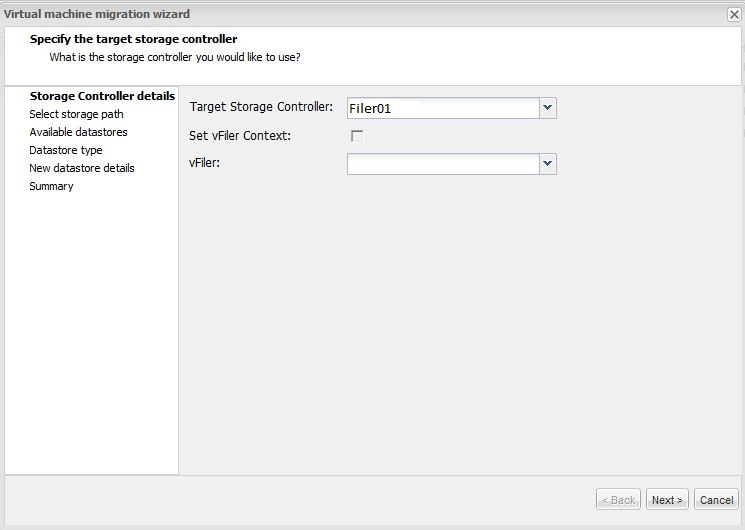
Aligning Virtual Machines Lets go through the process of aligning a misaligned virtual machine using VSC4. First, we select the virtual machine that is misaligned and choose the migrate task. This opens the alignment wizard.
Choose your filer.
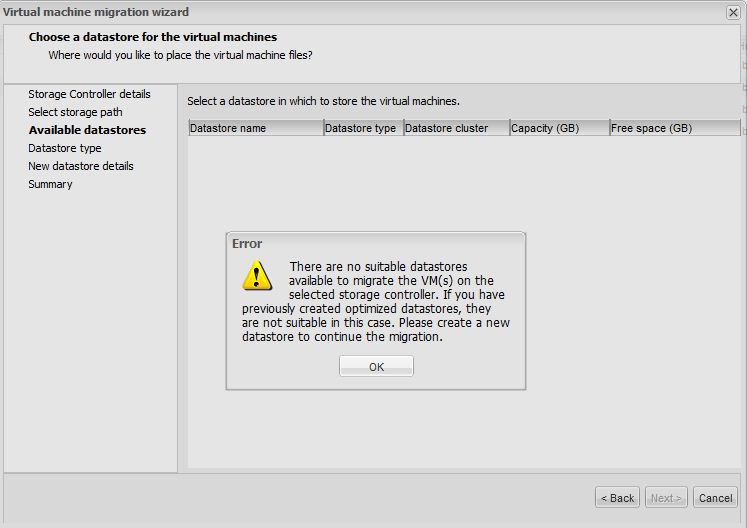
Next we choose a datastore. If we already have a functionally aligned datastore with an offset that’s the same as your unaligned virtual machine’s offset, you can select an existing datastore. If you don’t have an existing datastore that will align with your vm, you’ll receive an error message like the one below. If that’s the case, create a new datastore from the wizard.
Choose the datastore type.
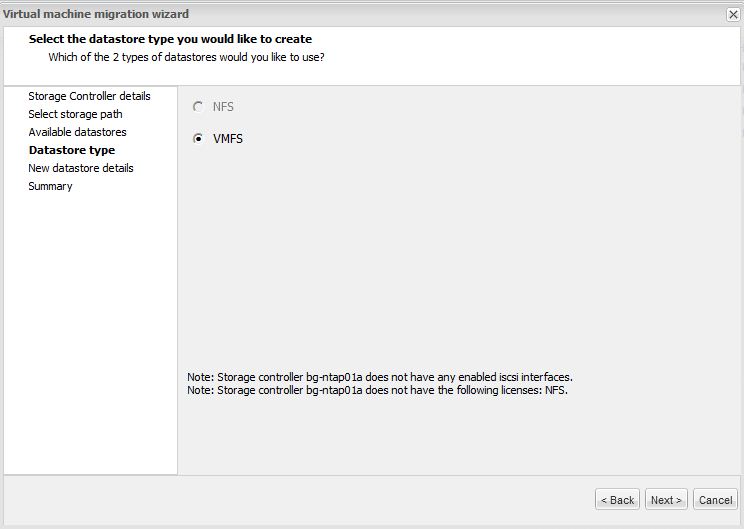 In our case we’ll create a new datastore.
In our case we’ll create a new datastore.
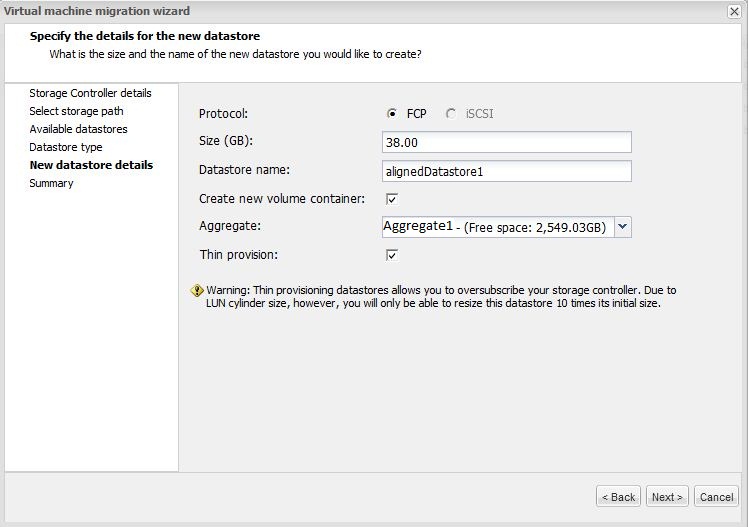 Once the migration is complete you’ll see your virtual machine in a new datastore and it will be aligned. Notice how the virtual machine offset matches the name of the new datastore that was created. Offset 7 was put into the AlignedDatastore1_optimized_7 datastore.
Once the migration is complete you’ll see your virtual machine in a new datastore and it will be aligned. Notice how the virtual machine offset matches the name of the new datastore that was created. Offset 7 was put into the AlignedDatastore1_optimized_7 datastore.

Now you can rest easy, knowing that your virtual machines are not suffering performance issues due to unaligned disks, and no downtime was required to do so.