
I was fortunate enough to get to spend an hour with Dmitriy Sandler from Nimble Storage to see what all the fuss was about with their product and more specifically their Cache Accelerated Sequential Layout (CASL) File System.
Hardware Overview
Let’s cover some of the basics before we dive into CASL. The storage array comes fully loaded with all the bells and whistles, out of the box. All the software features are included with this iSCSI array and include items such as:
- App Aligned Block Sizes
- Inline Data Compression
- Replication
- Instant Snapshots
- Thin Provisioning
- Zero Copy Clones
- Non-Disruptive Upgrades
- Scale Out to Storage Cluster
And this list goes on ad on. WAN replication for instance is very efficient due to the inline compression that is done during the writes.
Additional Specs can be seen below.
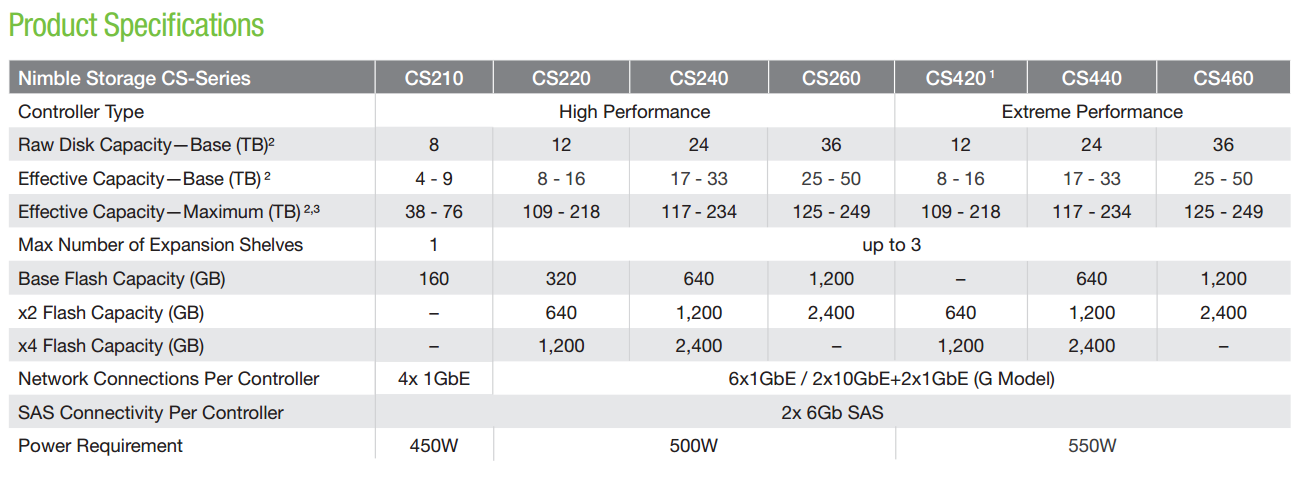
I would like to point out that the Nimble Arrays use Active-Standby Controllers which seems like a bit of a waste of capacity, but is AWESOME if you have a failure. It was pointed out to me that many Active-Active Controller systems end up having a significant performance impact during a failure because the controllers are overloaded. This shouldn’t be the case with a Nimble Array.
File System
So the features are nothing to sneeze at on their own right, but what differentiates Nimble from other storage arrays? The Nimble philosophy is that Hybrid storage is the right way to handle 95% of storage workloads. All flash arrays are expensive and the wear involved on SSDs is a limitation. All Spinning Disk arrays typically just don’t have that performance uumph that companies want these days. So what is the best way to use both SSDs and Spinning Disks?
‘Enter CASL
 CASL stands for Cache Accelerated Sequential Layout. The name says it all here. The file system is specifically written to make the most out of a hybrid design. Lets look at a typical write sequence first.
CASL stands for Cache Accelerated Sequential Layout. The name says it all here. The file system is specifically written to make the most out of a hybrid design. Lets look at a typical write sequence first.
Writes are sent to the device in multiple block sizes depending on the application using the device. Nimble arrays don’t care what the block sizes are and will accept any block sizes thrown at it. However, each volume can be automatically tuned for the specific application’s block size to optimize both performance and capacity efficiency. The blocks enter the PCIe NVRAM device on the array and are immediately copied to the Standby Controller across a 10Gb Bus. Once both controllers have the write in NVRAM, the write is acknowledged making for some very snappy response times and low latency for application writes.
Now that the writes are in NVRAM they are individually compressed in memory before ever writing to any disks. The data is “serialized” into a 4.5MB stripe and is evenly laid out across the entire set of SAS disks. This sequential write is pretty quick due to the fact that the data is written sequentially which limits the seek times necessary on random writes. Whats really cool about this process is that the CASL algorithm looks at the origin of the disk writes and puts them next to each other on disk. During a read operation there is a high likelihood that these writes will be retrieved together as well which will help read performance.
Pretty neat huh? But wait a second, what about those SSD’s in the system? We skipped them during this process. Well, during the write to the SAS disks, the CASL algorithm looks to find “Cache Worthy” data and segments it into smaller stripes for the SSDs and writes a copy to them as well. A graphic of this process is found below.
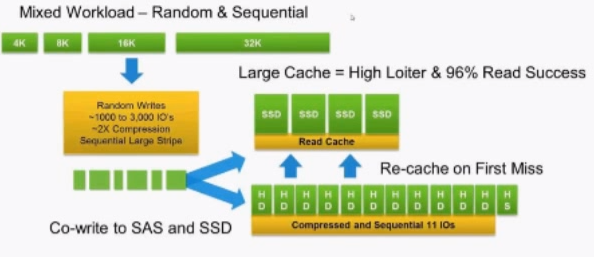
Courtesy of Nimble Storage
Reads, are done first from the NVRAM which is a nice add!. Many times data that is just written is often read right away so having NVRAM able to be read from is a fast way to handle reads. NVRAM can’t store a lot of data however so reads immediately are done based off the data in the SSDs. On the first cache miss, data is copied up from the spinning disks to the SSDs again, along with a prefetch of surrounding relevant blocks to accelerate subsequent application read requests.
Because CASL is built around SSDs, all writes are done in a full read/delete page, eliminating any write amplification. Since SSDs are just a cache, there is no need to waste any of them for hot-spares or RAID, offering a much higher usable capacity and lower $/GB. This also allows Nimble to use MLC drives whereas most systems are still bound to higher cost eMLC or SLC technology.
Garbage Collection
When I first heard of the CASL filesystem and how writes are done, I didn’t think that the writes to spinning disks were that much different from the Netapp Write Anywhere File Layout (WAFL) but digging into the garbage collection, the difference becomes clearer.
WAFL opportunistically tries to dump NVRAM to disk in the available open blocks similarly to CASL. The problem becomes when blocks are modified in WAFL, the blocks become very fragmented like swiss cheese. CASL has the same challenge but during Garbage Collection, these blocks are pulled back into NVRAM and re-written sequentially which keeps the system running nice and smooth.
Unlike WAFL, CASL is built as a fully Log Structured Filesystem (LFS). In other words, every time data is written down to disk, it’s done so in an optimally sized sequential stripe offering great write performance (thousands of IOPS from 7.2K drives) but also the ability to maintain performance over time as the system is filled up by intelligently leveraging the low-priority but always-on Garbage Collection engine.