I was pretty unsure of the value proposition from DriveScale in the weeks preceding Tech Field Day 12. Maybe the reason is because I’m not a Hadoop expert by any means. They have a pretty interesting idea though, so I wanted to make sure others were clear about what their solution was capable of.
In a virtualized world, we’re pretty familiar with decoupling disks from our storage. It’s done via storage arrays that present iSCSI, Fibre Channel, NFS or whatever. Once we’ve presented a pool of disks to our hypervisor, we can carve up small virtual disks to be used with our virtual machines. In a Hadoop world, we want to have direct access to our drives so that HDFS can manage the storage. For this, we usually have rack mounted pizza box type servers with a certain amount of storage in them and then we can add multiples of them to form a cluster. DriveScale wanted to give HDFS some extra flexibility by allowing a pool of disks to be added, or removed to our servers.
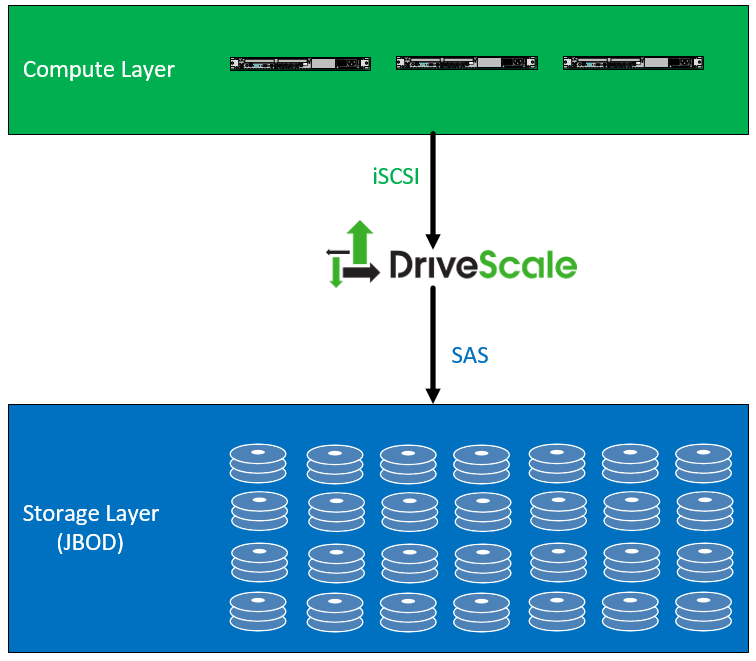
In the example below, we see a compute layer which is any number of physical servers, probably only providing compute and memory. Those servers attach to a DriveScale adapter (which is a one rack unit, four node server) attached via iSCSI. The DriveScale Adapter connects to direct attached JBOD (Just a Bunch of Disks) via a SAS connection.
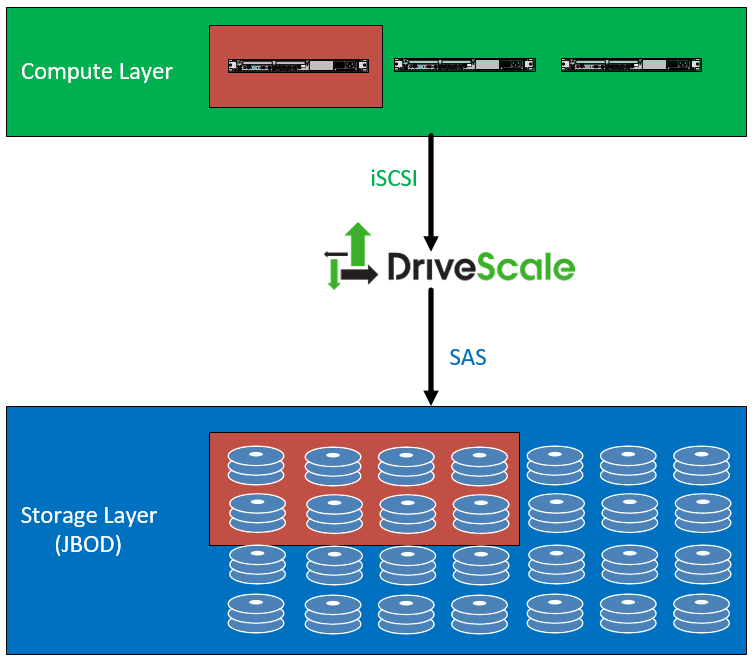
So when you have connected everything, you can assign a group of disks to one of your servers for use with a Hadoop cluster. Drive sizes, speeds, models, etc can be swapped out, for the cluster and moved between servers if needed. The example below shows that a group of eight disks were assigned to a single compute node.
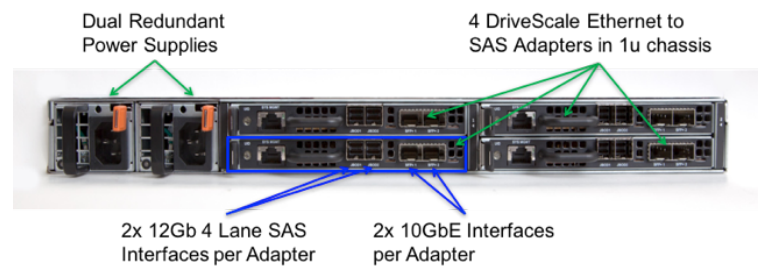
The DriveScale Adapter is shown below and contains dual power supplies and four DriveScale ethernet to SAS Adapters in the 1U chassis. DriveScale wants to use unused capacity in the top of rack switches for this iSCSI connection. It does not require any quality of service to the switches but does require the use of jumbo frames for the iSCSI traffic.
Summary
DriveScale seems like an interesting solution for Hadoop workloads. It’s going to give a Hadoop shop some much needed flexibility for their hardware but has a pretty specific use case and won’t work for everyone. You might not see these guys like a Dell EMC or HP which is in almost every enterprise data center, but they might have a serious play for those shops focused on Hadoop.