You’ve built your Kubernetes cluster(s). You’ve built your apps in containers. You’ve architected your services so that losing a single instance doesn’t cause an outage. And you’re ready for cloud scale. You deploy your application and are waiting to sit back and “profit.”
When your application spins up and starts taking on load, you are able to change the number of replicas to handle the additional load, but what about the promises of cloud and scaling? Wouldn’t it be better to deploy the application and let the platform scale the application automatically?
Luckily Kubernetes can do this for you as long as you’ve setup the correct guardrails to protect your cluster’s health. Kubernetes uses the Horizontal Pod Autoscaler (HPA) to determine if pods need more or less replicas without a user intervening.
Horizontal Pod Auto-scaling - The Theory
In a conformant Kubernetes cluster you have the option of using the Horizontal Pod Autoscaler to automatically scale your applications out or in based on a Kubernetes metric. Obviously this means that before we can scale an application, the metrics for that application will have to be available. For this, we need to ensure that the Kubernetes metrics server is deployed and configured.
The Horizontal Pod Autoscaler is implemented as a control loop, checking on the metrics every fifteen seconds by default and then making decisions about whether to scale a deployment or replica-set.
The scaling algorithm determines how many pods should be configured based on the current and desired state values. The actual algorithm is shown below.
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
If you haven’t heard of Horizontal Pod Autoscaler until now, you’re probably thinking that this feature is awesome and you can’t wait to get this in your cluster for better load balancing. I mean, isn’t capacity planning for your app much easier when you say, “I’ll just start small and scale under load.” And you’re right in some sense. But also take careful consideration if this makes sense in your production clusters. If you have dozens of apps all autoscaling, the total capacity of the cluster can get chewed up if you haven’t put the right restrictions on pods. This is a great time to revisit requests and limits on your pods, as well as setting autoscale limits. Don’t make your new autoscaling app, a giant “noisy neighbor” for all the other apps in the cluster.
Horizontal Pod Auto-scaling - In Action
Prerequisites
Before you can use the Horizontal Pod Autoscaler, you’ll have to have a few things in place.
- Healthy/Conformant Kubernetes Cluster
- Kubernetes Metric Server in place and serving metrics
- A stateless replica-set so that it can be scaled
Example Application
To show how the HPA works we’ll scale out a simple Flask app that I’ve used in several other posts. This web server will start with a single container and scale up/down based on load. To generate load, we’ll use busybox with a wget loop to generate traffic to the web server.
First, to deploy our web server. I’m re-using the hollowapp flask image and setting a 100m CPU limit with the imperative command:
kubectl run hollowapp --image=theithollow/hollowapp:allin1-v2 --limits=cpu=100m
In this case, we’ll assume that we want to add another replica to our replica-set/deployment anytime a pod reaches 20% CPU Utilization. This can be done by using the command:
kubectl autoscale deployment [deployment name] --cpu-percentage=20 --min=1 --max-10
In my lab, I’ve deployed the flask container deployment, and you can see that there is virtually no load on the pod when I run the kubectl top pods command.

Before we start scaling, we can look at the current HPA object by running:
kubectl get hpa

In the above screenshot, you can see that there is an HPA object with a target of 20% and the current value is 1%.
Now we’re ready to scale the app. I’ve used busybox to generate load to this pod. As the load increases the CPU usage should also increase. When it hits 20% CPU utilization, the pods will scale out to try to keep this load under 20%.
In the gif below there are three screens. The top left consists of a script to generate load to my web containers. There isn’t much useful info there so ignore it. If you want to generate your own load, deploy a container in interactive mode and run:
while true; do wget -q -O- http://[service name] > /dev/null 2>&1; done
The upper right shows a --watch on the hpa object. Over time, you’ll see that the HPA object updates with the current load. If the CPU load is greater than 20%, you’ll then see HPA scale out the number of pods. This is displayed in the bottom shell window which is running a --watch on the pods.
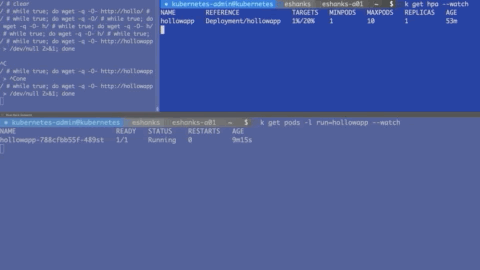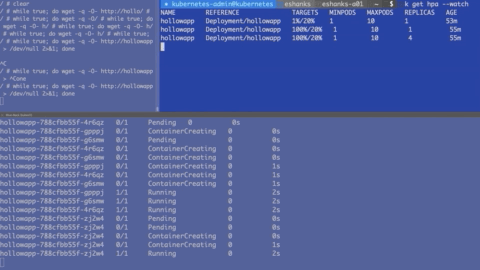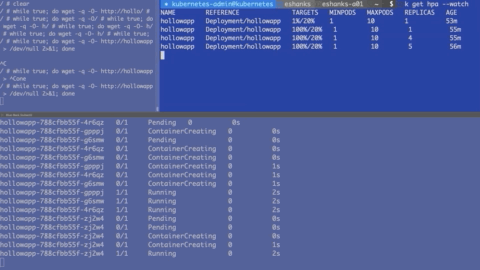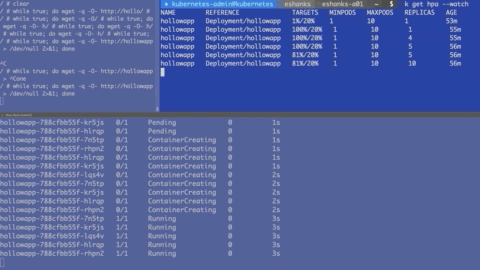
After the number of pods hits 10, it no longer scales since that the maximum number of pods we allowed in the autoscale command. I should also note that after I stopped generating load, it took several minutes before my pods started to scale back down, but they will scale down again automatically.
Summary
The Kubernetes Horizontal Pod Autoscaler is a really nice feature to let you scale your app when under load. Its not always easy to know how many resources your app will need for a production environment, and scaling as you need it can be a nice fix for this. Also, to give back resources when you’re not using them. But be careful not to let your scaling get out of control and use up all the resources in your cluster. Good luck!