The focus of this post is on pod based backups, but this could also go for Deployments, replica sets, etc. This is not a post about how to backup your Kubernetes cluster including things like etcd, but rather the resources that have been deployed on the cluster. Pods have been used as an example to walk through how we can take backups of our applications once deployed in a Kubernetes cluster.
Pod Backups - The Theory
Typically, when I’m talking about backups, the “theory” part is almost self-explanatory. If you deploy a production workload, you must ensure that it’s also backed up in case there is a problem with the application. However, with Kubernetes, you can certainly make the argument that a backup is not necessary.
No, this doesn’t mean that you can finally stop worrying about backups altogether, but Kubernetes resources are usually designed to handle failure. If a pod dies, it can be restarted using replica-sets etc. Also, it’s possible that a human makes an error and a deployment gets removed or something. Again, this is probably easily fixed by re-deploying the pods through a Kubernetes manifest file stored in version control for safe keeping.
What about state though? Sometimes our pods contain state data for our application. This is really where a backup seems most appropriate to me in a Kubernetes cluster because that state data can’t be restored through redeploying your pods from code. Users may have logged into your app, created a profile, etc and this is important data that needs to be restored if the app is to be considered production. My personal views on this (yours may vary) is that if you have stateful data, perhaps that data should be stored outside of your Kubernetes cluster. For example if your app writes to a database, maybe a services such as Amazon RDS might be a better place to store that data than a pod with persistent volumes. I’ll let you make this decision.
It is also possible to use backups for reasons other than disaster recovery. Maybe we’ve got a bunch of pods deployed but are migrating them to a new cluster. Backup/restore processes might be an excellent way for migrating those apps.
Pod Backups - In Action
For the demo section of this post, we’re going to use a tool called “Velero” (formerly named Ark) which is open-sourced software provided by Heptio. The tool will backup our pod(s) to object storage, in this case an S3 bucket in AWS, and then restore this pod to our Kubernetes cluster once disaster strikes.
Setup Velero
Before we can do anything, we need to install the velero client on our workstation. Much like we installed the kubectl client, we need a client for velero as well. Download the binaries and place them in your system path.
Once the client has been installed, we need to run the setup, which does things like deploy a new namespace named velero and a pod. We’ll also configure our authentication to AWS so we can use a pre-created S3 bucket for storing our backups.
The code below shows the command run from my workstation to setup Velero in my lab. You’ll notice I’ve set a provider to AWS, entered the name of an S3 bucket created, specified my aws credentials file with access to the s3 bucket and then specified the AWS region to be used.
velero install \
--provider aws \
--bucket theithollowvelero \
--secret-file ~/.aws/credentials \
--backup-location-config region=us-east-1
After running this command, we can checkout whats happened in our kubernetes cluster by checking out the velero namespace. You can see there is a deployment created in that namespace now thanks to the velero install command.

OK, velero should be ready to go now. Before we can demonstrate it we’ll need a test pod to restore. I’ve deployed a simple nginx pod in a new namespace called “velerotesting” that we’ll use to backup and restore. You can see the details below.

Backup Pod
Time to run a backup! This is really simple to do with Velero. To run a one-time backup of our pod, we can run:
velero backup create [backup job name] --include-namespaces [namespace to backup]

That’s it! Our backup is being created and if I take a look at the S3 bucket where our backups are stored, I now see some data in this bucket.
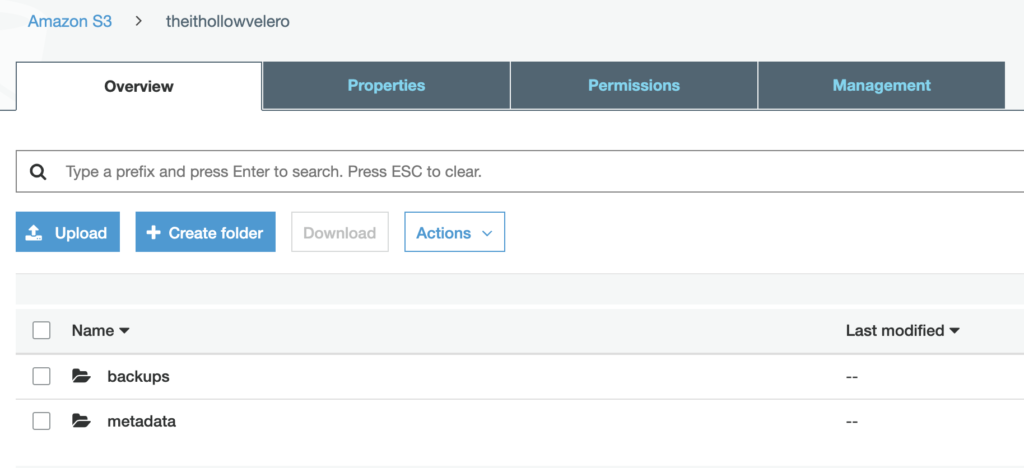
I wouldn’t be doing Velero enough justice to leave it at this though. Velero can also run backups on a schedule and instead of backing up an entire namespace, backups can be created based on labels of your pods as well. To find more information about all the different capabilities of Velero, please see their official documentation. This post is focusing on a 1 time backup of an entire namespace.
Restore Pod
Everything seems fine, so let’s change that for a second. I’ll delete the namespace (and the included pods) from the cluster.

Here is our nginx container that is no longer working in our cluster.
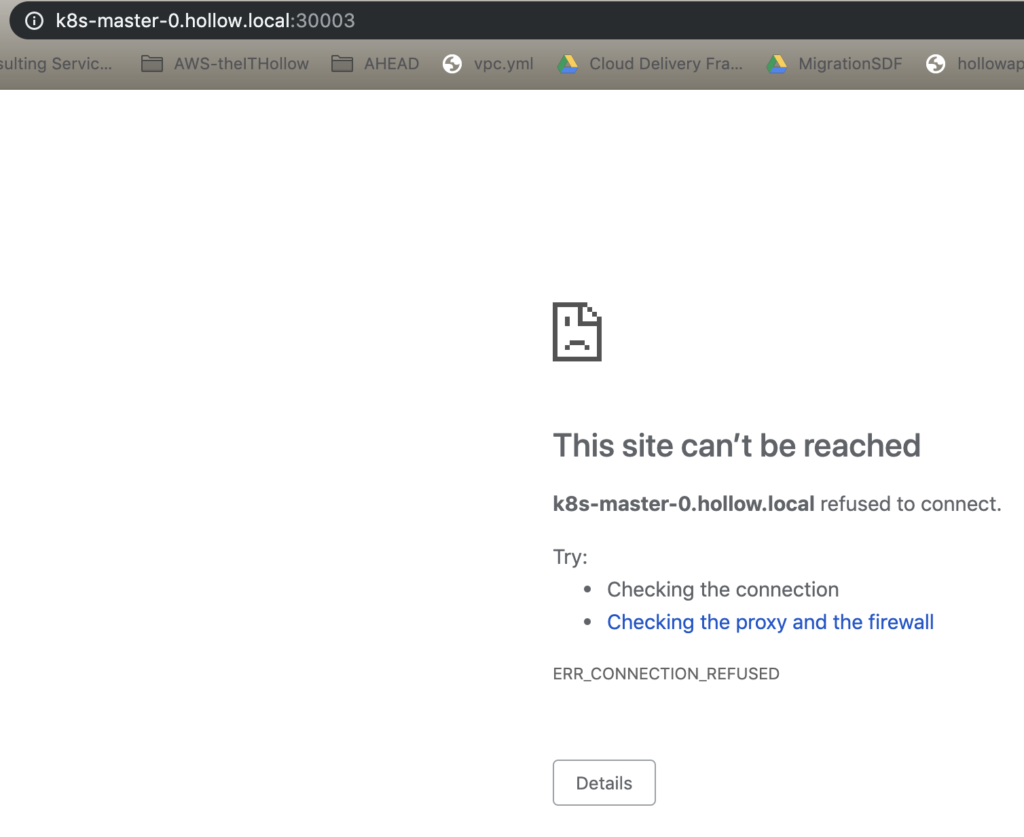
Oh NO! We need to quickly restore our nginx container ASAP. Declare an emergency and prep the bridge call!
To do a restore of our pods and namespace, we’ll run:
velero restore create --from-backup [backup name]

Just in case you can’t remember the name of your backup, you can also use velero to show your backups via the get command if you need to review your backups.

Let’s check on the restore now. Here’s our nginx site.
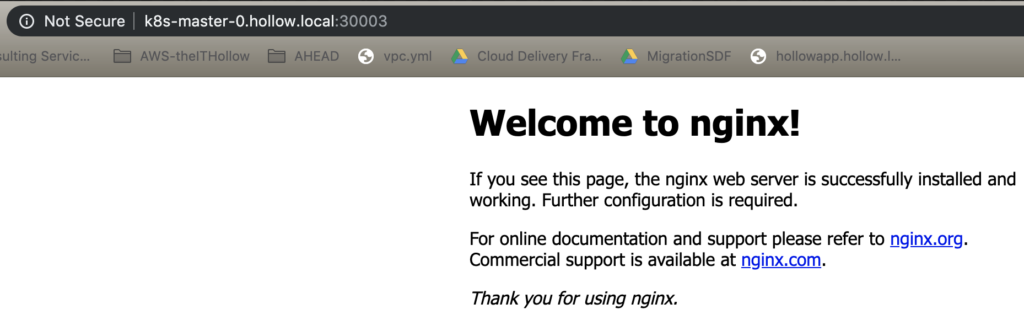
Summary
I know this seems like a silly example since our nginx pod is really basic, but it should give you an idea of what can be done with Velero to backup your workloads. A quick note, that if you are using a snapshot provider to check and see if its supported. https://velero.io/docs/v1.0.0/support-matrix/
If you plan to use your Kubernetes cluster in production, you should plan to have a way to protect your pods whether through version control of stateless applications or with backups and tools like Velero.