If you’ve just gotten started with Kubernetes, you might be curious to know how the desired state is achieved? Think about it, you pass a YAML file to the API server and magically stuff happens. Not only that, but when disaster strikes (e.g. pod crashes) Kubernetes also makes it right again so that it matches the desired state.
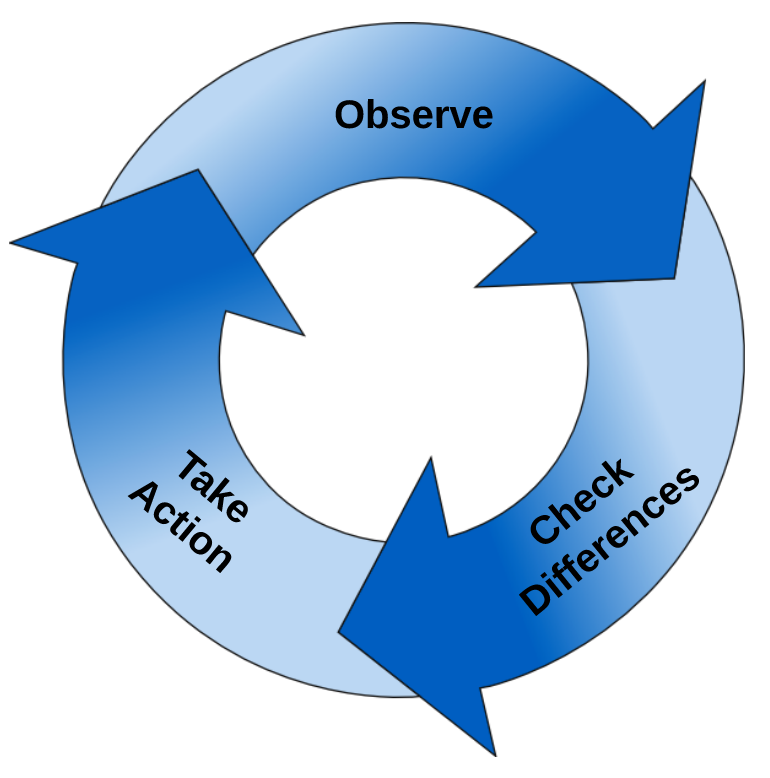
The mechanism that allows for Kubernetes to enforce this desired state is the control loop. The basics of this are pretty simple. A control loop can be though of in three stages.
- Observe - What is the desired state of our objects?
- Check Differences - What is the current state of our objects and the differences between our desired state?
- Take Action - Make the current state look like the desired state.
- Repeat - Repeat this over and over again.
OK, control loops look simple enough right? Now Kubernetes doesn’t have a single control loop, but many loops all running simultaneously. Each of these loops have a specific set of tasks to handle. For example, the Deployment controller watches for new Deployments to be created and then does its job of creating ReplicaSets. The ReplicaSet controller has its own loop that sees a new ReplicaSet is desired and does its job to create new Pod specs. The Pod controller does its job by creating new pod specs which the Kubelet will then deploy. You can see how these control loops can be strung together to converge on a desired state.
The control loop isn’t the only mechanism used to drive a desired state. You might be thinking to yourself, “Hey, all these control loops running at the same time seems inefficient and probably put a lot of strain on the API server to return these checks.” Well, you’d be right, if these loops kept happening every second. The API server would be overwhelmed with requests. So in order for these checks to happen, but not overwhelm the API server, they are run less frequently, such as five minute increments.
OK, a check every five minutes shouldn’t overwhelm the API server but now you have a new question. “We can’t wait 5 minutes for each of these checks to happen; that’s way too slow for us to fix issues and deploy new resources. So how does it work faster?”
The answer is an informer. Think of an informer like an event hook that notifies something about a change that has happened. The informer can speed up the whole process. Take the example of the Deployment again. Once the deployment is created, the informer can trigger the Deployment Control loop to fire so the process starts immediately without waiting for the schedule to kick it off again. Once the deployment control loop finishes and creates the ReplicaSet specification, an informer can tell the ReplicaSet control loop to fire again and so on.
Between the schedule that ensures the control loop runs periodically/ catches anything that might have been missed, and the informer which tells the loops to run “right now,” we have a pretty powerful solution.
Build Native K8s Apps
These control loops can do more than just manage our Kubernetes clusters. They can be a powerful mechanism for you to develop your own applications that run natively on Kubernetes. Perhaps you would create your own control loops to take action whenever a custom resource is created? If you’d like to see an example of this in action, take a peak at whats going on with the ClusterAPI project.
The ClusterAPI plans to use Kubernetes constructs such as Control Loops, Custom Resource Definitions, and pods to deploy new k8s clusters when provided with a configuration. Pretty slick huh?
What else could you use a control loop to build? And should you leverage the power of Kubernetes to run it?