If you’ve been on the operations side of the IT house, you know that one of your primary job functions is to ensure High Availability (HA) of production workloads. This blog post focuses on making sure applications deployed on a vSphere Kubernetes cluster will be highly available.
The Control Plane
Ok, before we talk about workloads, we should discuss the Kubernetes Control plane components. When we deploy Kubernetes on virtual machines, we have to make sure that the brains of the Kubernetes cluster will continue working even if there is a hardware failure. The first step is to make sure that your control plane components are deployed on different physical (ESXi) hosts. This can be done with a vSphere Host Affinity Rule to keep k8s VMs pinned to groups of hosts or anti-affinity rules to make sure two control plane nodes aren’t placed on the same host. After this is done, your Load Balancer should be configured to point to your k8s control plane VMs and a health check is configured for the /healthz path.
At the end of your configuration the control plane should look similar to this diagram where each control plane node is on different hardware, and accessed through a load balancer.
Worker Node HA
Now that our cluster is HA, we need to make sure that the worker nodes are also HA, and this is a bit trickier to work with. We’ve already discussed that our Kubernetes nodes (Control Plane Nodes/ Worker Nodes) should be spread across different physical hosts. So we can quickly figure out that our cluster will look similar to this diagram.
This is great, but now think about what would happen if we were to deploy our mission critical Kubernetes application with a pair of replicas for High Availability Reasons. The deployment could be perfect, but its also possible that the Kubernetes scheduler would place the deployment like this example below.
YIKES! The Kubernetes scheduler did the right thing and distributed our app across multiple Kubernetes nodes, but it didn’t know that those two worker nodes live on the same physical host. If our ESXi Host #1 were to have a hardware failure, our app would experience a short outage while it was redeployed on another node.
How do we solve for this issue?
Configure Kubernetes Zones
Lets re-configure our cluster to be aware of the underlying physical hardware. We’ll do this by configuring “zones” and placing hardware in them. For the purposes of illustrating this process, we’re going to configure two zones and ESXi-1 will be in Zone 1, and the other two ESXi hosts will be in Zone 2.
NOTE: I’m not advocating for un-even zones, but to prove that Kubernetes will distribute load across zones evenly, I wanted to put an un-even number of nodes in each zone. For example, if I had three zones and put each host in its own zone, the k8s scheduler would place pods across each node evenly, which is what it would do even if there were no zones. Demonstrating with an un-even number should display this concept more clearly.
Create VMware VM/Host Affinity Rules
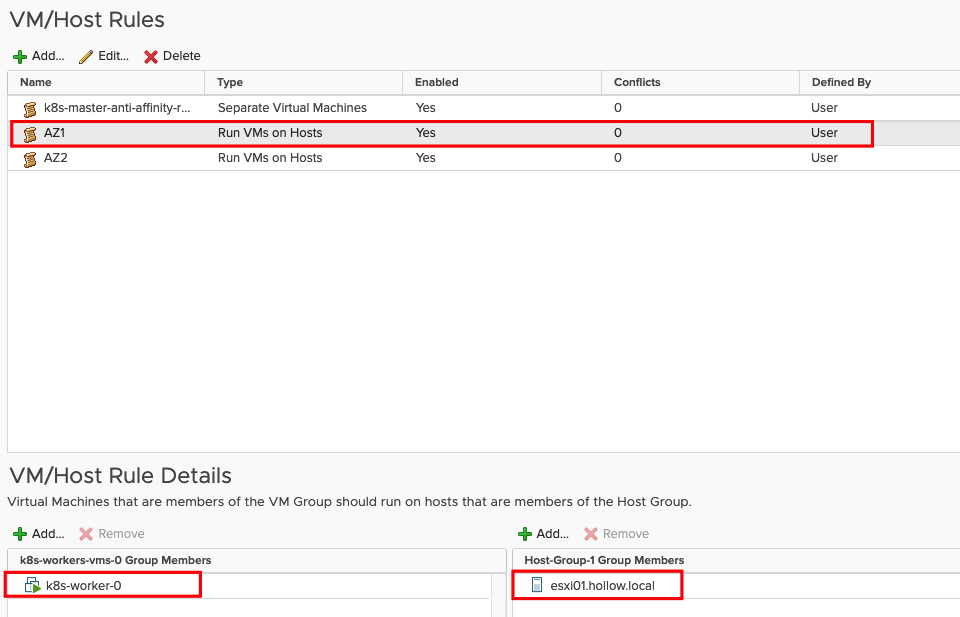
Whenever we have applications that need to be placed on different ESXi hosts for availability, we use vSphere affinity rules. Here I’ve created two rules (1 for each zone) and placed our k8s vms and ESXi hosts in those zone names.
For example, the screenshot below shows our zone (AZ1) that has our k8s-worker-0 VM pinned to the esxi01 HOST.
Then we create a second zone and pin my remaining two worker nodes on different hosts, ESXi02/ESXi03.
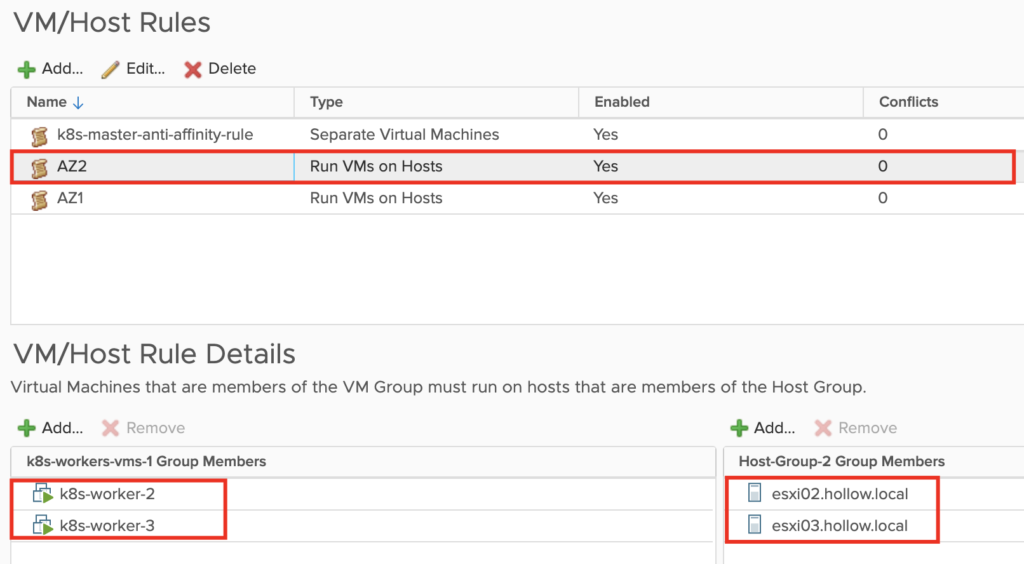
My home lab now looks like this, where I’ve pinned my k8s vms to nodes. You can see that the problem mentioned above could still happen, but we’ve ensured that our worker nodes won’t be moved between zones by vSphere DRS though.
Configure Kubernetes Zone Topology
UPDATE:
The process seen below can also be done automatically with a combination of vSphere Tags and a properly configured vSphere cloud provider. That process can be found here: https://vmware.github.io/vsphere-storage-for-kubernetes/documentation/zones.html
Now we need to let Kubernetes know about our physical topology. The first thing we need to do is to enable a feature gate on our Kubernetes API server and Scheduler. This requires us to be running Kubernetes 1.16 or later, so if you’re running an older version, you’ll need to upgrade.
Set the feature flag EvenPodsSpread on each of your kube-apiserver and kube-scheduler nodes to enable the feature. This is likely a configuration that should be added to the static pod manifests in your cluster. If you’re not sure where these are, check /etc/kubernetes/manifests on your control plane nodes. Thats where they’ll be if you followed this post on deploying Kubernetes on vSphere.
Excellent, now the next thing we want to do is to add a label to our Kubernetes worker nodes that correspond to whatever zone name we want. I’m using AZ1 and AZ2. So I’ve applied a new label to my worker nodes named “zone” and their zone ID, as seen below.
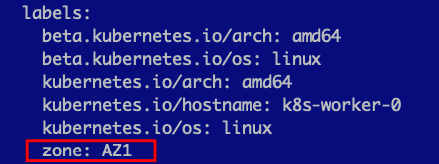
Repeat that process on each of your Kubernetes workers, keeping in mind what ESXi host they belong with. As you can see my labels match my vSphere config.

Use Zones with our Deployments
Now our Kubernetes worker nodes are in the appropriate zones, our VMs are spread across hosts within those zones and our API server and Scheduler components are aware of zone topologies. The next step is to configure our applications to respect our zones. Within the pod spec of our deployment manifests, we need to use the “topologySpreadConstraints” config and set the topologyKey to our zone label, which was “zone”.
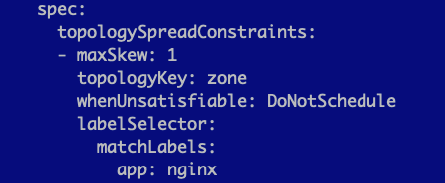
You can see my nginx deployment in full, below. This is the same deployment manifest used in the getting started guid e, when we learned about Deployments. We’ve just added the topology section.
apiVersion: apps/v1 #version of the API to use
kind: Deployment #What kind of object we're deploying
metadata: #information about our object we're deploying
name: nginx-deployment #Name of the deployment
labels: #A tag on the deployments created
app: nginx
spec: #specifications for our object
strategy:
type: RollingUpdate
rollingUpdate: #Update Pods a certain number at a time
maxUnavailable: 1 #Total number of pods that can be unavailable at once
maxSurge: 1 #Maximum number of pods that can be deployed above desired state
replicas: 6 #The number of pods that should always be running
selector: #which pods the replica set should be responsible for
matchLabels:
app: nginx #any pods with labels matching this I'm responsible for.
template: #The pod template that gets deployed
metadata:
labels: #A tag on the replica sets created
app: nginx
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: nginx
containers:
- name: nginx-container #the name of the container within the pod
image: nginx:1.7.9 #which container image should be pulled
ports:
- containerPort: 80 #the port of the container within the pod
Did it work?
So I’ve deployed my mission critical app to my re-configured vSphere cluster. Lets see how the distribution came out in our cluster. We can see that there are six pods deployed across three nodes. The cool part is that we deployed three pods on worker-0 within AZ1, and three pods on the other two workers which are in AZ2. So while the number of ESXi nodes in each zone are un-even, the distribution of pods respected our zone boundaries, making our application highly available.

Other Considerations
This post was just supposed to help explain how the zones can be configured for Kubernetes clusters on vSphere. There are other considerations such as sizing to take into account. The example we used left un-even numbers of worker nodes in each zone. This means that AZ1 is likely to be full before AZ2 is. When this happens, the scheduler won’t be able to distribute the workloads across both zones and you may have an availability issue again. Zones should be similar in size to ensure that you can spread the pods out over those nodes.
Zones are great, but you can also use other topology labels such as regions if you need to break down your cluster further. Maybe you want to spread pods out over multiple regions as well as your zones?
Also, your vSphere environment is probably pretty flexible. An administrator might need to vMotion these workers to other nodes for maintenance. If that happens, Kubernetes won’t know about any zone topology changes. Be sure to keep your zone topology fairly static or you could encounter issues.
Summary
Kubernetes deployments will try to spread out your pods across as many nodes as possible, but doing so doesn’t necessarily mean that they are highly available. Setting your zones up correctly can increase the availability of your applications deployed on Kubernetes. Good luck setting up your environment!