Determining which type of RAID to use when building a storage solution will largely depend on two things; capacity and performance. Performance is the topic of this post.
We measure disk performance in IOPS or Input/Output per second. One read request or one write request = 1 IO. Each disk in you storage system can provide a certain amount of IO based off of the rotational speed, average latency and average seek time. I’ve listed some averages for each type of disk below.
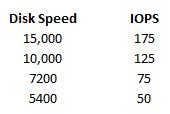
sources: http://www.techrepublic.com/blog/datacenter/calculate-iops-in-a-storage-array/2182 http://www.yellow-bricks.com/2009/12/23/iops/ http://en.wikipedia.org/wiki/IOPS
So for some basic IOPS calculations we’ll assume we have three JBOD disks at 5400 RPM, we can assume that we have a maximum of 150 IOPS. This is calculated by taking the number of disks times the amount of IOPS each disk can provide.
But now we assume that these disk are in a RAID setup. We can’t get this maximum amount of IOPS because some sort of calculation needs to be done to write data to the disk so that we can recover from a drive failure. To illustrate lets look at an example of how parity is calculated.
Lets assume that we have a RAID 4 system with four disks. Three of these disks will have data, and the last disk will have parity info. We use an XOR calculation to determine the parity info. As seen below we have our three disks that have had data written to them, and then we have to calculate the parity info for the fourth disk. We can’t complete the write until both the data and the parity info have been completely written to disk, in case one of the operations fails. Waiting the extra time for the parity info to be written is the RAID Penalty.

Notice that since we don’t have to calculate parity for a read operation, there is no penalty associated with this type of IO. Only when you have a write to disk will you see the RAID penalty come into play. Also a RAID 0 stripe has no write penalty associated with it since there is no parity to be calculated. A no RAID penalty is expressed as a 1.
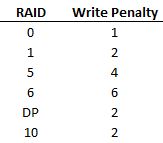
RAID 1
It is fairly simple to calculate the penalty for RAID 1 since it is a mirror. The write penalty is 2 because there will be 2 writes to take place, one write to each of the disks.
RAID 5
RAID 5 is takes quite a hit on the write penalty because of how the data is laid out on disk. RAID 5 is used over RAID 4 in most cases because it distributes the parity data over all the disks. In a RAID 4 setup, one of the disks is responsible for all of the parity info, so every write requires that single parity disk to be written to, while the data is spread out over 3 disks. RAID 5 changed this by striping the data and parity over different disks.
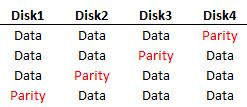
The write penalty ends up being 4 though in a RAID 5 scenario because for each change to the disk, we are reading the data, reading the parity and then writing the data and writing the parity before the operation is complete.
RAID 6
RAID 6 will be almost identical to RAID 5 except instead of calculating parity once, it has to do it twice, therefore we have three reads and then three writes giving us a penalty of 6.
RAID DP
RAID DP is the tricky one. Since RAID DP also has two sets of parity, just like RAID 6, you would think that the penalty would be the same. The penalty for RAID DP is actually very low, probably because of how the Write Anywhere File Layout (WAFL) writes data to disk. WAFL will basically write the new data to a new location on the disk and then move pointers to the new data, eliminating the reads that have to take place. Also, these writes are written to NVRAM first and then flushed to disk which speeds up the process. I welcome any Netapp experts to post comments explaining in more detail how this process cuts down the write penalties.
Calculating the IOPS
Now that we know the penalties we can figure out how many IOPS our storage solution will be able to handle. Please keep in mind that other factors could limit the IOPS such as network congestion for things like iSCSI or FCoE, or hitting your maximum throughput on your fibre channel card etc.
Raw IOPS = Disk Speed IOPS * Number of disks
Functional IOPS = (Raw IOPS * Write % / RAID Penalty) + (RAW IOPS * Read %)
To put this in a real world example, lets say we have five 5400 RPM disks. That gives us a total Raw IOPS of 250 IOPS. (50 IOPS * 5 disks = 250 IOPS).
If we were to put these disks is a RAID 5 setup, we would have no penalty for reads, but the writes would have a penalty of four. Lets assume 50% reads and writes.
(250 Raw IOPS * .5 / 4) + (250 * .5) = 156.25 IOPS