Early this year I saw a challenge drop in my inbox for VMware vExperts to deploy a Plex server with Tanzu Community Edition (TCE). I hadn’t gotten to try out TCE yet, and had never messed with Plex so this sounded like a fun adventure. The goal was to architect an entire solution as though this Plex server was going to be a production app that a company might run their business off of. Which means, that I needed to not only get the thing working, but start making some steps to operationalize it. You know of course that production systems come with security, observability, auto-scaling, an incident response routine, etc. Well, this is my home lab so we’ll have to assume that this is my minimum viable product, because as you’ll see, I could still put a lot of work in here.
If you’d like to see some of the YAML manifests that I used to deploy packages, clusters, and plex, you can check out this github repository.
Conceptual Design
If this is a real app, it probably could use a read conceptual design. Here were my abbreviated requirements, constraints, risks, and assumptions.
Requirements
- Must be able to access the Plex server from a local address on my home network.
- Backups must be kept offsite
Constraints
- Solution must fit within existing hardware specs. No additional home lab purchases allowed.
- Must run on Tanzu Community Edition
Assumptions
- This lab will be torn down after building it.
In a real world, there would be much more to deal with including risks to the project but this is a good enough start for a home lab build.
Architecture
The general layout of the solution can be found below.
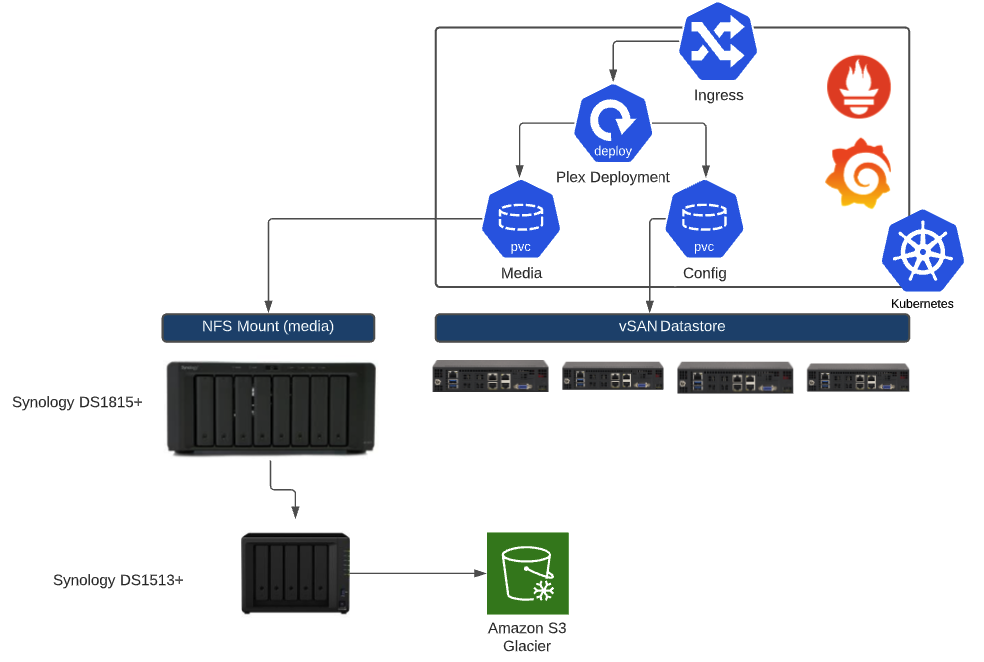
Tanzu Community Edition - Kubernetes Cluster Deployment
The real goal of this challenge was to get familiar with Tanzu Community Edition (TCE). TCE lets me deploy a Kubernetes cluster in a couple of different ways including a management cluster / workload cluster model or a single cluster. Since I was trying to mimic a more production type deployment, I opted for deploying a management cluster with a development workload cluster consisting of a single control plane node to reduce my resource utilization, and a production cluster where my app will run full time. The production cluster will run a highly available control plane load balanced by kube-vip. This load balancer is configured automatically through TCE.
Obviously I don’t need this in the lab, but in a production world, I’d want a development cluster where I can test things out without affecting my active users. I’ll assume I can get away with a small dev cluster for this scenario.
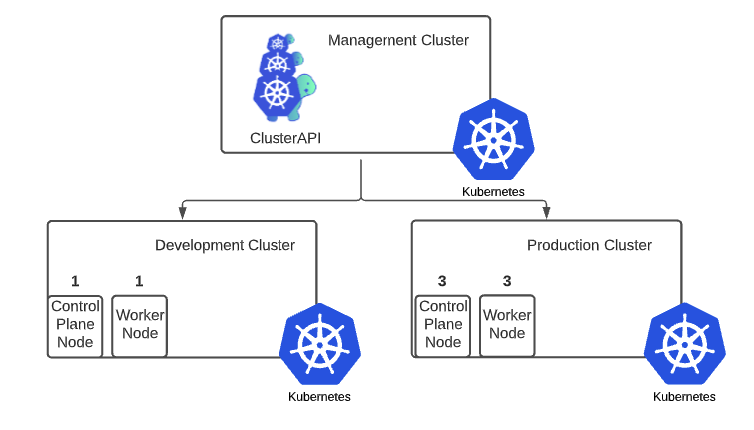
The process of deploying a TCE cluster is documented here, but you might also take a look at my installation notes post. There are a couple of workarounds needed as of the time of this writing, to get the management cluster deployed correctly on vSphere.
Load Balancing
So my control plane nodes are load balanced with kube-vip. There wasn’t anything special I needed to do to make this work other than completing the cluster deployment. However, in my environment I’ll need a load balancer periodically in order to present my Kubernetes applications to my users.
In my situation, I opted for deploying Metal-lb. This is a load balancer solution that is deployed within the Kuberenetes cluster.
Package Deployments
Before I deploy the Plex server, I should deploy some tools I’ll need to operate the application. Tanzu Community Edition provides “packages” that can be installed with some simple commands. I’ve deployed a few of these packages to meet my operational requirements.
- Contour - I deployed the Contour Ingress Controller so that I can present my applications through a reverse proxy. I could probably get away with not using this, but this is a good pattern to get into. If I was deploying my solution on a hyperscaler like AWS I’d get billed for each of my load balancers, and an ingress controller will make sure that I only need a single load balancer for all of the apps in my cluster. Also I can get additional layer 7 capabilities if I really needed them.
- Cert-Manager - I might as well deploy cert-manager as well so that I can get certificates created for my applications including plex. Using Cert-manager with contour means that I can add certificates to my applications without re-configuring my applications. The best certificates are the ones you don’t think about.
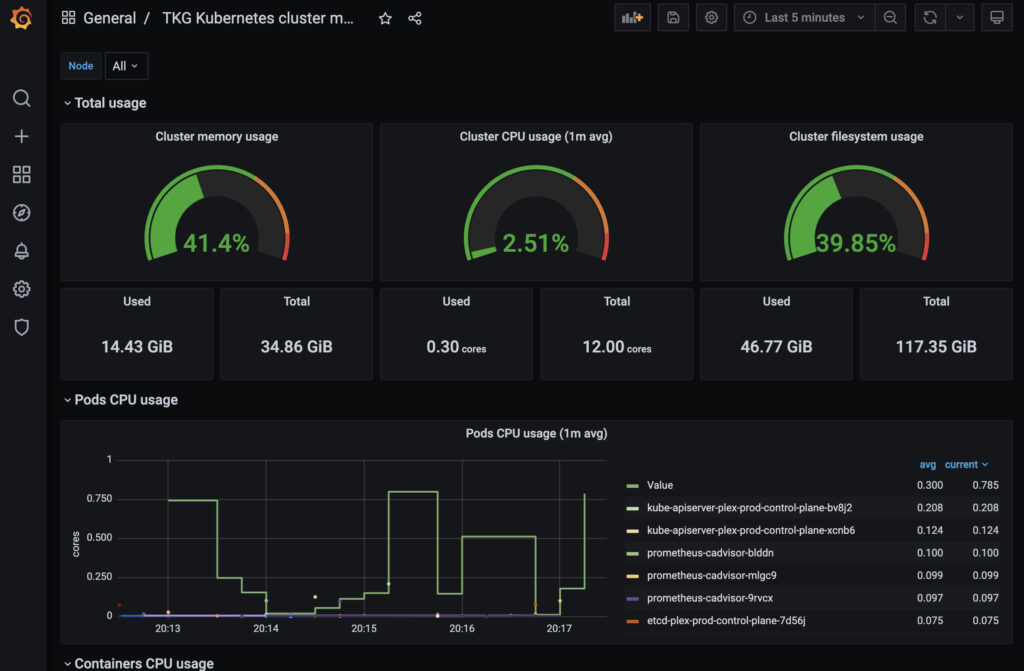
- Prometheus - I deployed the prometheus package so that I can see the performance of my application. If I have an outage because my apps ran out of resources, its still on me so I need a way to at least see if not alert on those rules.
- Grafana - Since I’m deploying Prometheus, I’m also deploying the Grafana plugin so that I can get visualizations around the prometheus data.
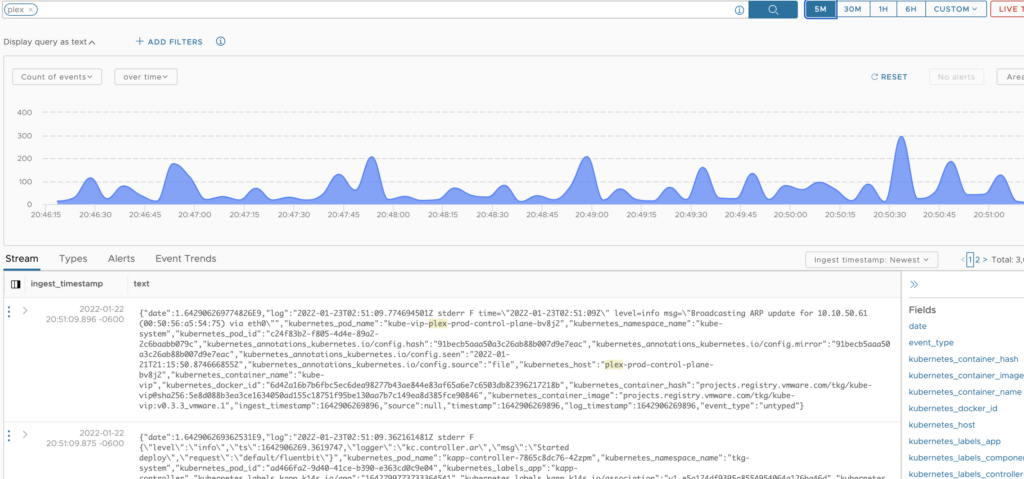
- Fluentbit - Logs are critical to production applications and this includes audit logs. While deploying the TCE clusters, I enabled audit logging so I can be sure that I’m the only administrator playing with configuration settings on my cluster. Fluentbit will forward the logs from my clusters to a log aggregation solution like vRealize Log Insight.
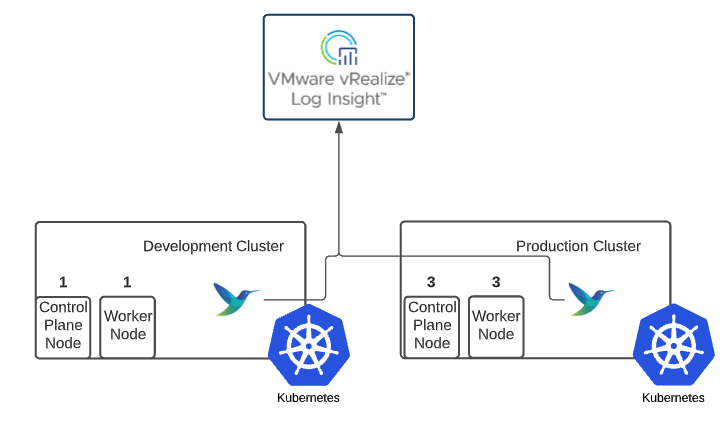
Storage
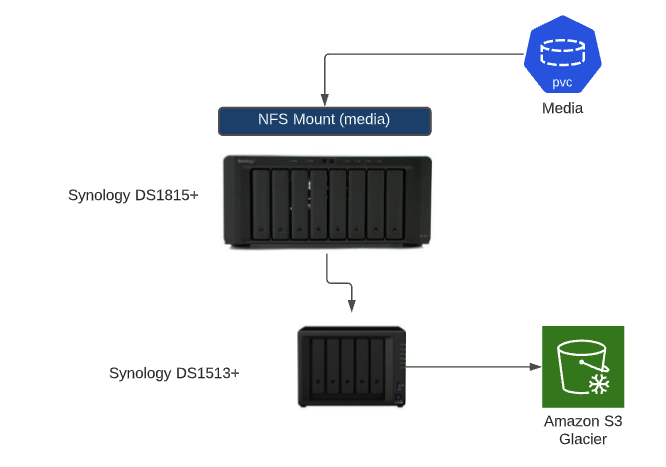
Before I deploy my plex server, I also need to consider how storage will be laid out. The plex server is looking for some persistent storage to store two specific things. The first is the media that you’re sharing through plex. All those movies, TV shows, music albums have to be read by Plex so that they can be watched or listened to. For this, I created an NFS mount on my Synology Disk Station. After building the NFS mount on the Synology, I can drop my media files on my array and when I deploy the plex server, plex will mount this media directory. So even if I delete, upgrade, re-configure, etc. my plex server, the media will still be safe and sound on my storage array. I can even move my plex server to different clusters/hardware as long as it can reach the NFS mount.
The second thing needed for persistent storage was the plex database . Since this is running a database I chose to store this on a vSAN persistent volume instead of NFS. My clusters were deployed into a vSphere environment so I can leverage Cloud Native Storage to request storage. In my case, I have a Kubernetes default storage class that allows me to request a Persistent Volume Claim, where in turn a persistent volume is created on vSAN and attached to my Kubernetes nodes, to be used by containers.
Disaster Recovery
I’m storing my Plex Server configurations in git so I’m actually not worried about my plex server at all. If I was concerned about it, I could use the Velero package provided by TCE so that I could run backups of my Kubernetes object and store them in an S3 bucket. However, in my case I’m ONLY worried about the media on my NAS. Everything else I can re-create if I had a failure but the media is critical.
My backup solution was outside of Kubernetes. I have a weekly backup that stores my media files on a second Synology array in my lab (yeah I have two, stop judging me) and that array has a monthly job where it will backup files to Amazon S3 for off site, long term storage.
Plex
Now it’s time to deploy Plex. I found several blog posts helpful, but the post the MOST helpful was this one from debontonline.com because it matched my lab environment really well. In this post, Mr. de Bont has laid out the kubernetes manifests pre-built with the ports required to operate Plex from other devices. I needed to modify my storage because I chose to use a persistent volume on vSAN for my configuration directory instead of NFS, but in other respects the YAML here was all that was needed to deploy my resources. Thanks to deploying Metal-lb and Contour first, I can even re-use the services and Ingress rules used in his post.
Note: The plex media server cam up and I could stream content. However, I did have an issue that I was unable to resolve, where the plex media server wasn’t registering with the service. My understanding was that if a plex claim [token] was added to the container environment variables that registration would happen after startup. I have yet to resolve this issue.
Beyond the Minimum Viable Product
It’s obvious that I wasn’t actually putting in the effort you would for a production application that a business depends on, but I tried to touch on a lot of it. I haven’t created customized dashboards in Grafana, or configured the appropriate alerts specific to my application (plex) in my log aggregation tool, but it’s a lab and I’m not getting paid to make improvements to this system all day long. :)
If this was really a production system I’d need to spend some more time on health checks, and network policies, and a secure deployment pipeline for updates, and some webhooks for my git repo. That list goes on and on. There are a million things to do for a real production application, but hopefully I covered the most common ones for getting an up up and running with a minimum amount of tools ready to observe and handle failures.