Clustering the vPostgres database is an important part of a fully distributed vRealize Automation install. The simple install only requires a single vRealize Appliance and an IaaS Server, but the fully distributed install requires many additional pieces including load balancers to ensure both high availability as well as handling extra load placed by users. The vPostgres database is included with the vRealize Automation appliances, but for a full distributed install, these must be modified so that there is an active and standby vPostgres database running on them. The primary vPostgres database will replicate to a standby read-only database.
VMware recently published a KB article to setup the vPostgres replication but didn’t show how to fail over the databases.
The Setup
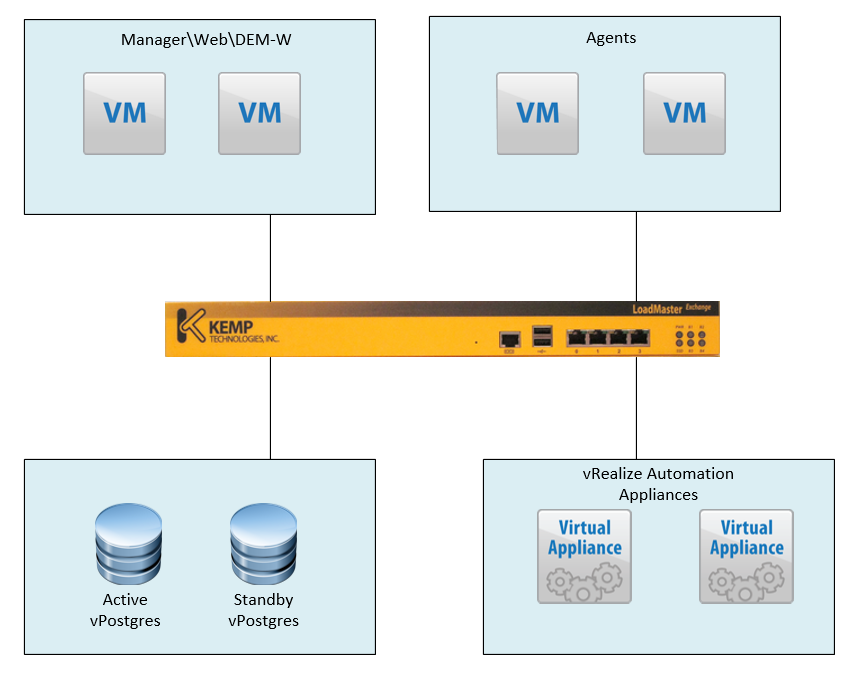
Just to level set, here is my environment. I’ve got a pair of vRealize Appliances, a pair of IaaS Servers running the manager, web services and Dems, a pair of windows server running the agents and last but not least, a pair of vPostgres appliances. These are all managed with a Kemp virtual load balancer.
I’m using the vi rtual Kemp Load Balancer in my lab and as you can see I’ve setup a virtual IP (VIP) for the vPostgress database with a name of “vPostgres” and my two vPostgress servers are listed as “Real Servers” on port 5480. The load balancing scheduler was set to a fixed weighting, meaning that all requests will go to the highest weighted server unless it is unavailable, at which point the second appliance will receive the requests. This is important to have configured correctly because the vPostgres servers will be ActivePassive. Sending requests to the Passive database will result in errors.

Failover the Database
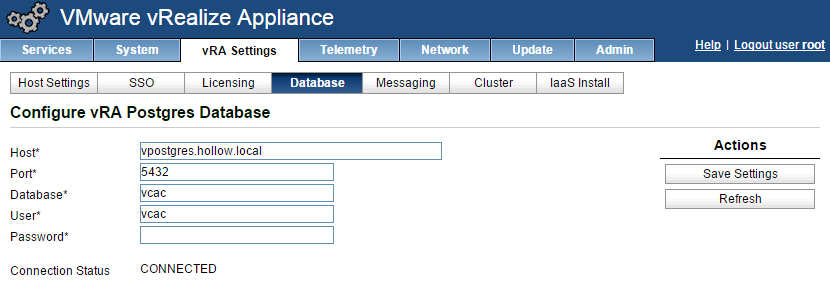
I used a highly complicated and sophisticated procedure to fail my Active vPostgres appliances… I powered it off. I went into my vRealize Automation Appliance to check the database status. To my surprise it shows a connection status of “Connected” as you can see from the screenshot below. I’m not sure what the vRA appliance uses to determine if the database connection status is connected or not, but if it’s just using a simple ping, then this makes sense.
I went to my vRealize Automation portal and still received my login screen. However when I tried to login it took a long period of time to log me in, and then finally displayed a error page.
Now that we’ve proven that things are breaking, lets fail over that database. SSH into the backup vPostgres appliance and change to the postgres user by running:
su - postgres
Next, run the commands to make the database readwrite. Be sure to change the directory to /opt/vmware/vpostgres/current/share since that’s where the scripts reside.
./promote_replica_to_primary
You’ll notice that the server shows “Server Promoting”.

Once the promotion is complete, the vRealize Automation portal works again as expected. Please note though that the load balancer started sending the requests to the backup appliance automatically because it was the only appliance available when the primary failed. If the primary vPostgres appliance were to become available again, the load balancer would start sending traffic to that one again, even though it is no longer the primary database. If the original primary appliance is fixed and powered back on, be sure to modify your load balancer rules before it comes back online.
Reset
Now that your backup vPostgres database is now the primary, you need to make the original appliance the backup. To do this, you can re-run:
./run_as_replica –h -b -W -U
This will make the appliance a read-only copy of the new primary vPostgres appliance.