vRealize Code Stream now comes pre-packaged with JFrog Artifactory which allows us to do some cool things while we’re testing and deploying new code. To begin this post, lets take a look at what an artifactory is and how we can use it.
An artifactory is a version control repository, typically used for binary objects like .jar files. You might already be thinking, how is this different from GIT? My Github account already has repos and does its own version control. True, but what if we don’t want to pull down an entire repo to do work? Maybe we only need a single file of a build or we want to be able to pull down different versions of the same file without creating branches, forks, additional repos or committing new code? This is where an artifactory service can really shine.
JFrog Artifactory
As I mentioned vRA Code Stream allows us to use JFrog Artifactory as well. to access this, go to the https://Your_vRA_Appliance/Artifactory. The login by default is:
Username: vmadmin
Password: vmware
From there, You can add your own repo under the Admin tab. I’ve created a Generic Repo for housing my files.
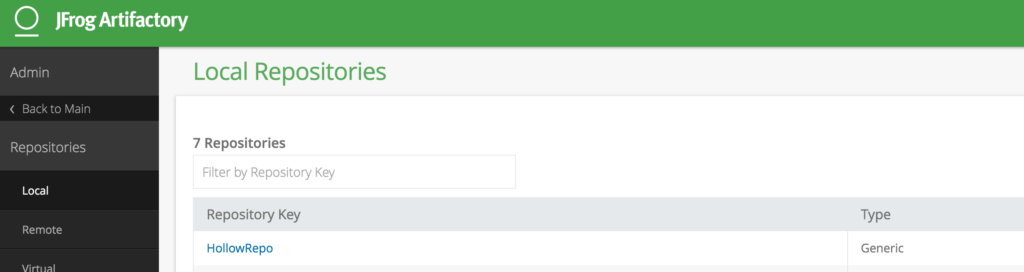
Now if we look at the Artifacts tab, we can see my new repo and I’ve added two different zip files. These zip files contain some files that I’m using for a web server.
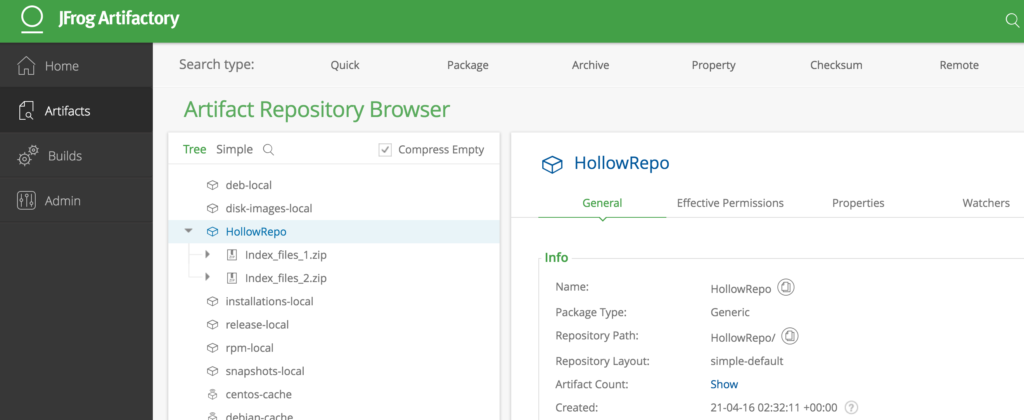
Next, I’ve added a property to each of the files in this repo. My first file I added the property named “Build” and a Value of “1.” My second file in the repo has the same property name of “Build” but the value is “2.”
Setup Artifactory with vRealize Automation
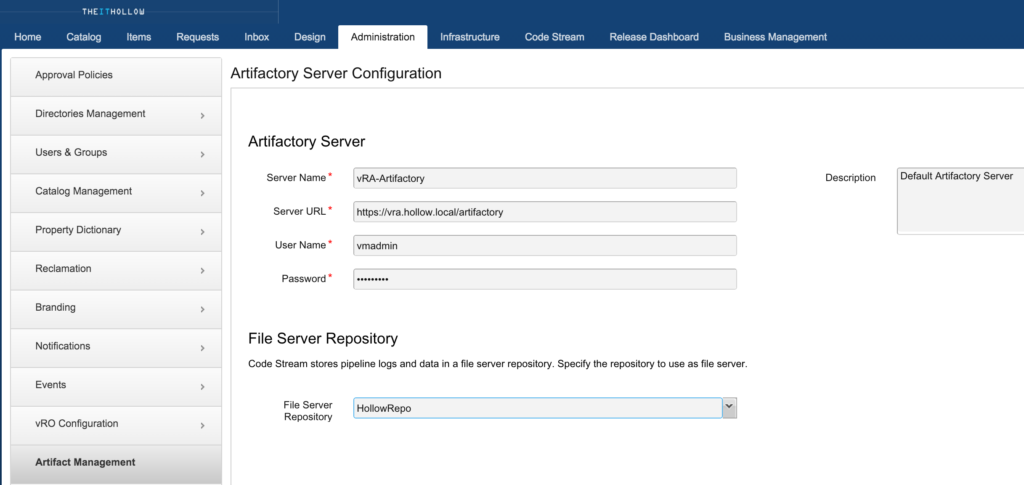
Go to the Administration tab –> Artifactory Management. Enter in a server name, and the url for your artifactory server, as well as the username and password.
Create Code Stream Pipeline
Now we can build a new Code Stream Pipeline. For this I’ve gone to the Code Stream tab, and then created a new pipeline. Give the pipeline a name, and description before moving on. HEY, YOU THERE! Enter a Description. Don’t skip over it, Enter a description! We’ll wait for you.
Next, I’ve added a property named “Build.” This is an input value that can be changed when the pipeline is executed. For our example, the version of the Build that is entered for the pipeline will match up with the value of the build files in Artifactory.
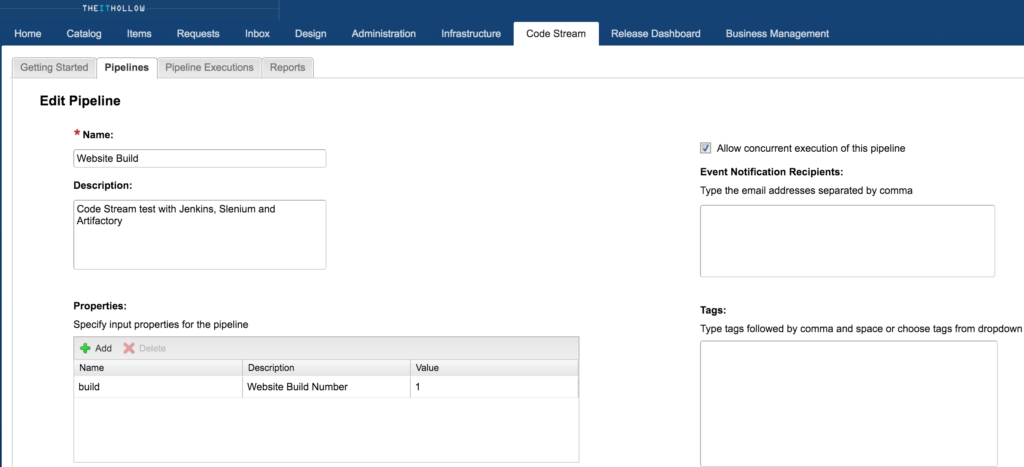
Next we need to add our development pipeline stages and tasks. The example below has several things going on, but the most relevant ones to this post are the “Resolve Artifact” and “Deploy Website Files.” Let’s take a closer look at the configuration of these two tasks.
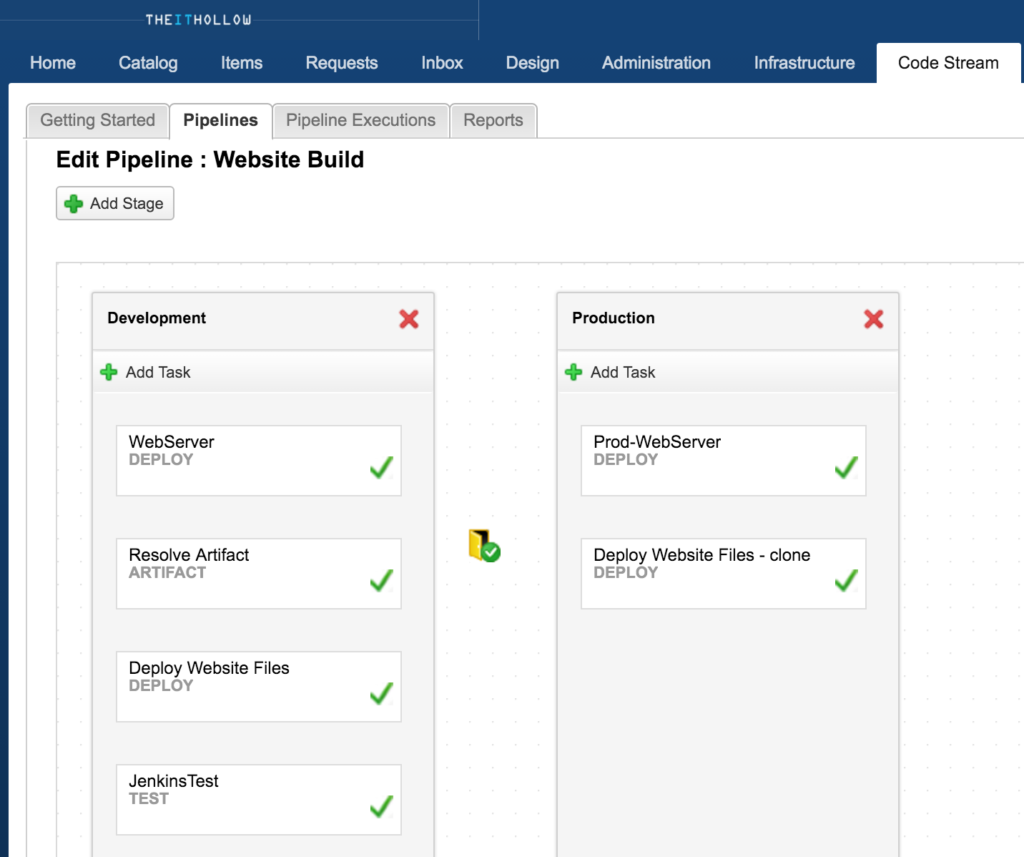
First, the “Resolve Artifact” task is going to search through artifactory to find the package, binaries or files that match our rules. You can see below that this task is going to look through the “HollowRepo” repository, for an object with a property named “Build” and the value of this property should equal to “${pipeline.build}.” This last value is a variable and it maps to the input variable we created when first setting up the pipeline.
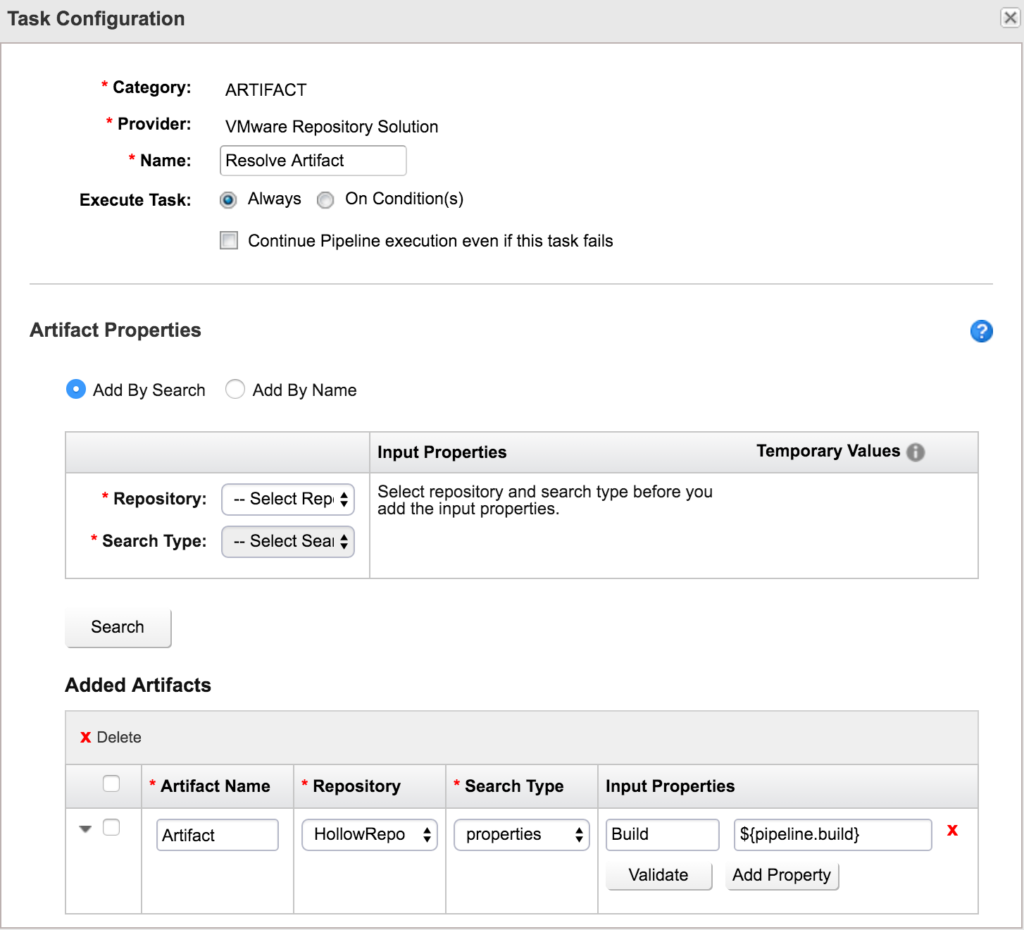
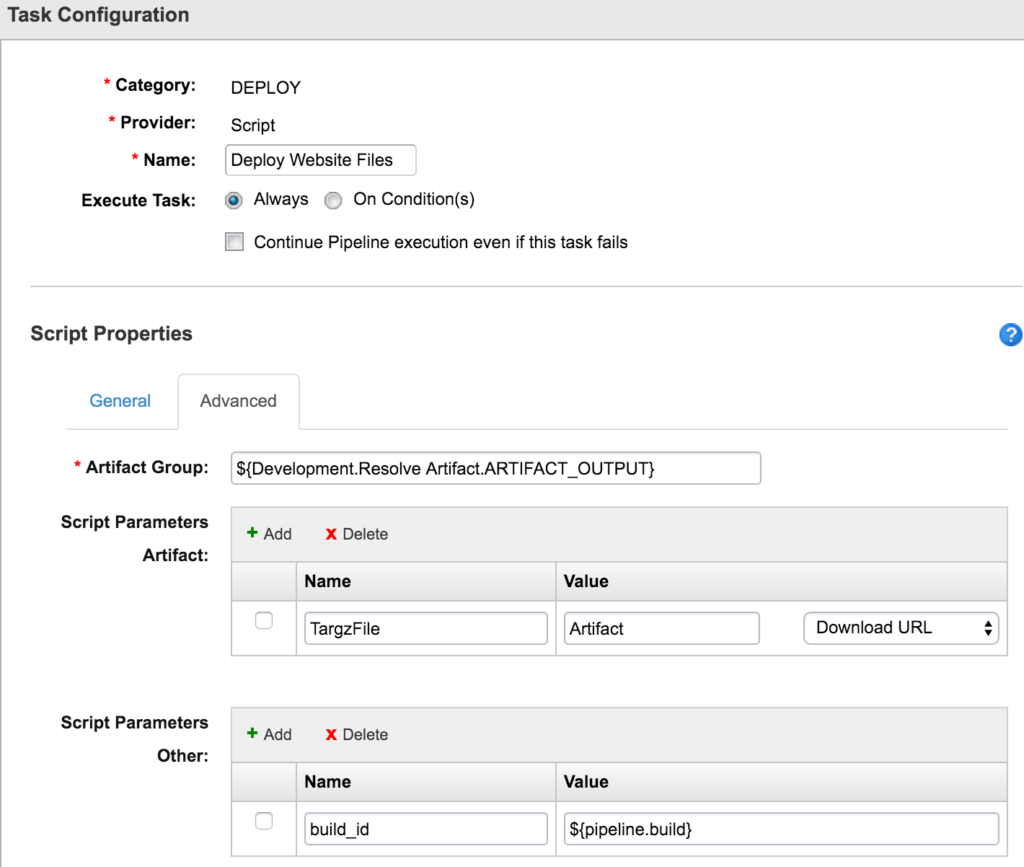
Now the next task’s job is to deploy some files onto a server of ours. Here the first screen displays some information about the server I’m deploying the files to, the login credentials and the script I use to grab the files, unzip them and put them in the right directory. Your mileage will vary here, but the main part to understand for this post is on the advanced tab setting.
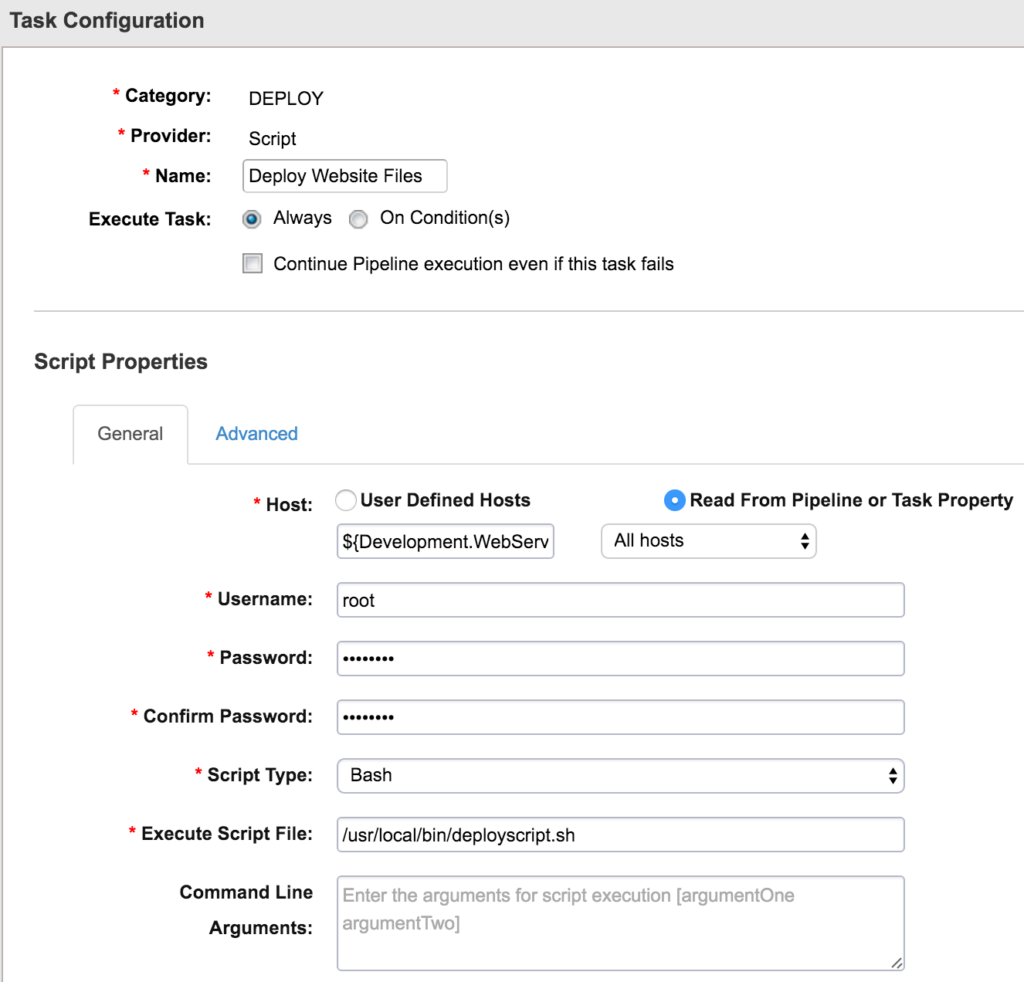
On the advanced tab, we’ll see a field called “Artifact Group.” Here I’ve got another variable called “${Development.Resolve Artifact.ARTIFACT_OUTPUT” which is the output of our Resolve Artifact task. Then I’ve got a few properties that I’m using in my script. The main thing to understand here is that the deploy task will deploy files that the “Resolve Artifact” task has found.
Run a Pipeline
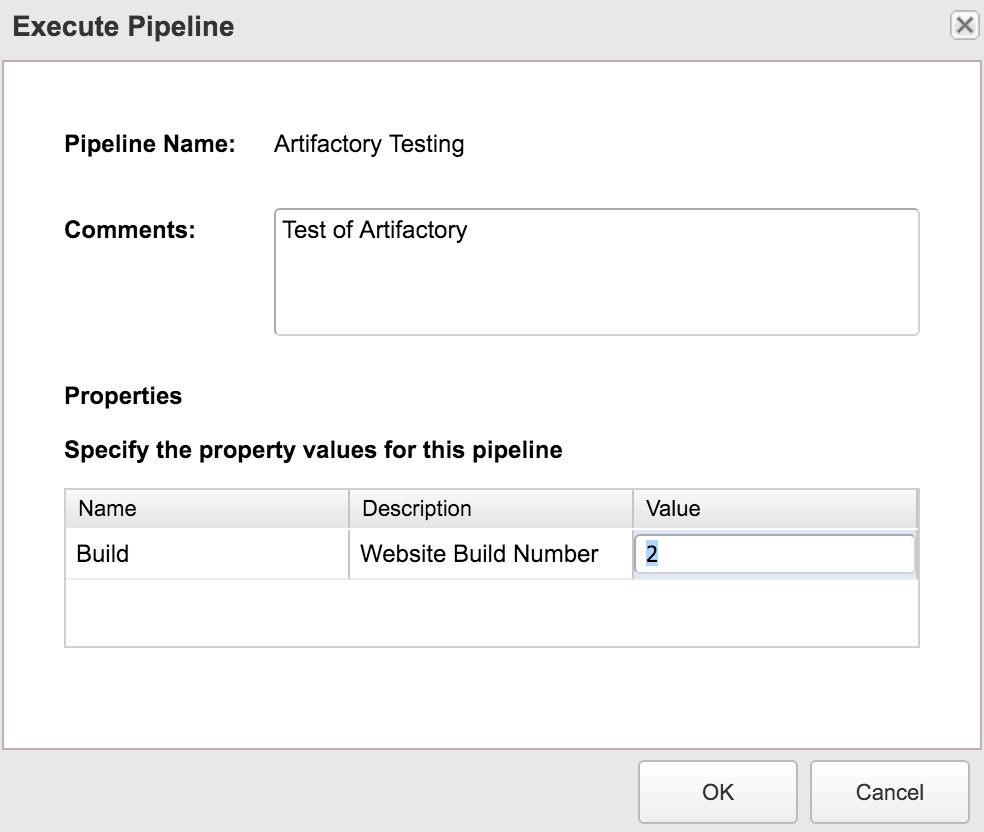
Now that we’ve got everything built, we execute the pipeline. We’re asked for a comment and we’ve learned our lesson about not putting in descriptions right!? And most importantly we can modify the build value that is our input property.
Summary
Ok, so why did we do this? Now we can use this pipeline to deploy new code to our web servers just by changing the value of the input property. Code stream will allow us to do neat stuff like get whatever artifact that you want for your test, deploy that on a new server spun up by vRA and tested with Jenkins. If it passes the Jenkins test, we can then do stuff like automatically deploy the code to production. The sky is the limit here with what you can do for a release pipeline. I’d love to hear how you did it in the comments.